
Pandasは高速処理ができるデータフレーム/ライブラリ、と紹介があると思いますがなんのこっちゃですよね。Pythonを勉強してもcsv操作、データ分析、グラフ化と色々やりたくなってきますが、Pandasを勉強するここれらのことも簡単にできるようになります。私もまだまだ勉強が足りないので、ここで紹介をしながら勉強を続けています。
目次
Pandasを覚えたい
PandasとNumpyって何が違うという疑問を持たれている方が多いと思いますが、Numpyは均質なデータを扱うことが多いです。高次元のデータを扱うことに適しているため、機械学習等に活用するライブラリとなっています。
それに対してPandasは様々なデータを扱うことに適しています。数値だけではなく様々な文字列にも対応することができます。日々処理しているデータは売上や商品の発注、数量、価格等さまざまと思いますし、各個人の売り上げデータや、多くのExcel、csvを整理したいニーズは多分にあるのではないでしょうか?。もちろんPythonのライブラリでもできることもありますが、Pandasを学ぶことによってより簡単にすることができると思います。
DataFrame(データフレーム)を知りたい
データフレームとはPandasが扱うデータ構造の1種です。DataFrameがPandasのデータ構造です。
| リスト | list | 基本の構造、異なるデータ種類も入れられる |
| タプル | tuple | listと同種類だが変更が付加 |
| 辞書 | dic | keyとvalueが組み合わさったデータの集合 順序は持たない |
| 配列 | ndarray | Numpyが扱うデータ構造、数値のみを要素に持つことが多い 数値以外も混ぜる場合はPandasを使用したほうがよい |
| データフレーム | DataFrame | Pandasが扱うデータ構造 データ型をいろいろまとめて処理することができる |
Pandasが定義するデータ構造は3種類あります。Numpyと違い3次元までしかありません。
シリーズ(1次元)、データフレーム(2次元)、パネル(3次元)となります。
ちなみにcsvから読み込まれたデータはデータフレームとなります。
実際にデータフレームを作ってみたのが下記となります。
import pandas as pd
df1 = pd.DataFrame(
{
'id':[101,102,103,104,105],
'name':["yamada","sato","inoue","sugita","suzuki"],
'score':[44,78,34,90,63]
}
)Numpyを使ってデータフレームを作ることもできます。
コラム、インデックス名を指定しています。
こちらのやり方も参考にしてください。
iimport numpy as np
import pandas as pd
array1 =np.arange(12).reshape([4,3])
df2 = pd.DataFrame(array1, columns =["A","B","C"], index=["a","b","c","d"])DaraFrame,Series,Listの変換をしたい
Pandasを活用していくうえで、2次元、1次元、リスト化と自由に変換して使っていきたくなると覆います。コードは下記となります。
# データフレームをリスト化する
df = pd.read_csv("data.csv", encoding='shift_jis')
list_sample = df['従業員番号'].to_list()この変換は色々な時に必須となるのですが、「ぷんたむの悟りの書」が丁寧に書かれていておすすめです。私もわからなくなったら参考にさせてもらってます。
またarrayをSeriesにしたい際に出るエラー
「Data must be 1-dimensional」は1次元じゃないと変換できないよ~、っていうエラーですが、時々arrayがnp.array([[1,2,4,5]])って[[ ]]と、[ が2つついてる時があるので要注意です。これなんじゃ?と思った人も多いかもしれませんが、これは2次元配列になっているため1次元に変換しないといけないのです。
b = a.flatten() # 1次元配列に変形したものをbに代入flatten()メソッドを用いて1次元に変換すればSeriesにもListにもすることができます。
また、DataFrameをilocを使ってSeriesに変換するときの注意点です。これはなかなかわかりにくいですが、numpyとPandasを併用したい際に覚えておくと損はないと思います。
ddtry = df_train.iloc[1:2,1:] # DataFrameになる
ddtry = df_train.iloc[1,1:] # SeriesになるDataFrameの情報を取得したい
情報の取得方法です。
行数・列数などを表示: df.info()
行数を取得: len(df)
列数を取得: len(df.columns)
行数・列数を取得: df.shape
全要素数(サイズ)を取得: df.size
ファイルの読み込み書き込み(Pandas)をしたい
Pandasでのデータの読み込み書き込みについては専用ページに移植しました。
下記を参考にしてください。
ファイルの読み込み(基本)をしたい
「jinkou.csv」を読み込んでみましょう。
※よかったらダウンロードしてお使いください。
都道府県別の人口推移のデータとなっています。この章ではこれを使ってサンプルコードを記述してあります。
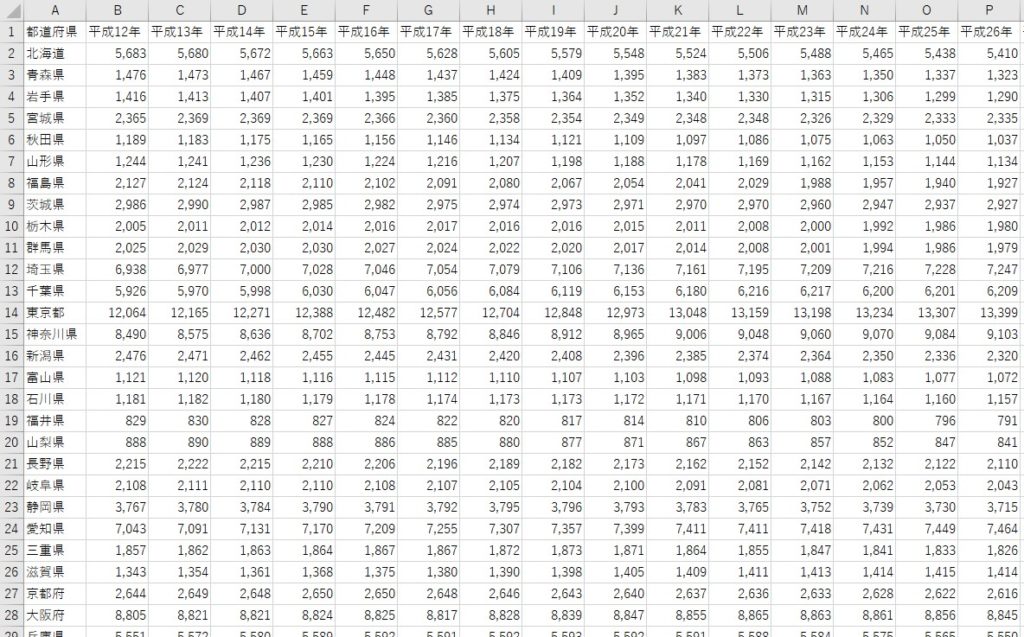
このデータを読み込むコードは下記となります。
import pandas as pd
df1 = pd.read_csv("jinkou.csv", encoding='shift_jis')
# エクセルデータの場合は下記となります
df1 = pd.read_excel('jinkou.xlsx')ここで少しポイントですが、読み込むデータはデータ型として日本語や数字風の文字列が混入していることが多いですよね。encoding=’shift_jis’を指定するとまずは読み込むことができます。
この指定をしたからといって文字列になるということはありません。このように指定してもPandasが便利なのは数値は数値型として認識しているところです。
ファイル読み込み(インデックス指定)をしたい
インデックスを指定させて読み込むことができます。先頭行がインデックスではないデータは比較的多いと思います。あまりインデックスを意識して作成されていないデータを読み込むときに非常に便利です。あとでもインデックス指定できますが、初心者のうちはこのように指定しておくと苦労を軽減することができますよ。
import pandas as pd
# 3行目,4列目をインデックスとして指定
df1 = pd.read_csv('jinkou.csv', header=3, index_col=4)複数ファイル読み込みをしたい
フォルダ内の複数ファイルを読み込むのに、いちいちファイル名を記述するのは面倒ですよね。そこでフォルダ内のデータを読み込むことができるやり方を別ページで紹介します。下記のカード型リンクから移動してくださいね。

Pandas書き出し
ファイルの書き出しをしたい
また、csvファイルへの書き込み(出力)、エクセルファイルでのセーブの方法は下記となります。もちろん名前は自由につけてくださいね。
df1.to_csv("jinkou_hohzon.csv",encoding='utf_8_sig')
df1.to_excel("jinkou_hozon.xlsx",sheet_name= df1.iloc[0,0])このとき、,encoding=’utf_8_sig’を入れるのが一つのポイントです。ファイルとして書き出したときに文字化けしていることを防ぐためです。
また、headerやindexが出力されてほしくない!、という場合は
引数でFalseにすると出力されなくなります。サンプルコードは以下となります。
df1.to_csv("jinkou_hohzon.csv",header = False, index = False)Excel Writerを使って高度にエクセルに書き出しをしたい
Excel Writerを使うともっと高度な保存ができます。
# 出力ファイル名を指定
excel_writer = pd.ExcelWriter('output.xlsx')
# シート名を指定してデータフレームを書き出す
dataframe1.to_excel(excel_writer, '従業員コード')
dataframe2.to_excel(excel_writer, '名前')
# 書き出した内容を保存する
excel_writer.save()Pandasでのデータを活用して名前を付けたブックを保存していきたい
# 部位別に書き出し ##################
# len(df1) 1つ多いから気を付けて!
b = len(df1)-1
for a in range(b):
n = df1.iloc[a,0]
file_name = str(n) + ".xlsx"
sheet_name = str(n)
# 出力ファイル名を指定
excel_writer = pd.ExcelWriter(file_name)
# シート名を指定してデータフレームを書き出す
df1.to_excel(excel_writer,sheet_name)
# 書き出した内容を保存する
excel_writer.save()
######################################また、名称を保存のたびに変更したい場合は下記を参考にしてください。

データフレームの確認をしたい
読み込んだらデータの確認をしてみましょう。DataFrameはheadというオブジェクトを持っているので、頭行数を指定して確認することができます。
df1.head(10)これで頭10行の確認をすることができます。ほかのやり方についてはコードを記載するのでトライしてみてください。
#後ろ行数の表示(この場合後ろ10行)
df1.tail(10)
#ColumnsはDataFrameのオブジェクトでコラムを表示します
df1.columns
#スライシングで取り出すことも可能
df1[5:9]
#平成12年だけ取り出す
df1["平成12年"] 様々な属性確認の手段の紹介です。読み込んだ後試してみてください。
| info() | データフレームサイズ、列名、データ数、nullの状況、データ型の情報が得られます |
| describe() | 数値データ列のみですが、件数、平均、標準偏差、最小値等を表示します |
| len() | データのサンプル数を表示します |
基本は以上となりますが、
私のおすすめの加工方法をご紹介します。
特にJypyterNotebookで活用できますが、下記となります。

このコードはまず最初にdf_fin.columns(この事例のデータフレームの名前がdf_fin)でindexを抜き出します。次にそれをコピペする感じで下に加え、削除したいindexを消去していく方法が一番簡単かと思います。
データの取り出し方/加工/削除をしたい
加工をしたい(インデキシング,スライシング)
Pandasデータフレームではデータの列名でアクセスすることも多いですが、
Numpy同様、インデキシング、スライシングでもアクセスできます。
| loc | 行ラベルと列ラベルからのアクセス |
| iloc | 行番号、列番号からのアクセス |
#locはラベル指定で取り出す(5番(6行目)から19番(20行目)まで取り出す)
df1.loc[5:19,"平成12年"]
#ilocで行列の範囲を指定(5~8番まで) ilocになるとなぜか12~19番まで
df1.iloc[12:20,5:9]
#ilocでピンポイントに指定
df1.iloc[10,2]
#様々な使い方
df1.iloc[:23,2]また、真偽型で受け取ることもできます
#大阪だけTrueで返されます
df1["都道府県"]=="大阪府"データをソートしたい
>>> # 行名に基づいてソート
>>> df.sort_index(ascending=False)
>>> # カラム名 (列名) に基づいてソート
>>> df.sort_index(axis=1, ascending=False)
>>> # B 列の値の小さい順 (昇順) にソート
>>> df.sort_values(by='B')
>>> # C 列の値の大きい順 (降順) にソート
>>> df.sort_values(by='C', ascending=False)削除をしたい
drop()関数で削除することもできます
# 1行目,3行目,5行目データを削除
df.drop(df.index[[1, 3, 5]])
# 1~4行目データを削除
df.drop(range(1, 5))
# 3列目データを削除
df.drop(df.columns[3],axis=1) # axis='columns'でも可
# 1列目と3列目データを削除
df.drop(df.columns[1,3],axis=1) # axis='columns'でも可
# 1列目~4列目を削除
df.drop(df.columns[range(1, 5)],axis=1)
# 都道府県列を削除
df.drop("都道府県",axis=1)
# 都道府県と平成12年を削除
df.drop(["都道府県","平成12年"],axis =1)行,列のIndex,Columnsを任意に変更したい
インデックスを変更する方法です。インデックスは読み込んだデータに付与されていることもありますが、後々のコーディングの際にわかりやすいインデックスに変えておきたいですよね。特にカタカナ等は面倒になることが多いです。
DataFrame.rename(index={'2020年': '2021年','令和2年': '令和3年'})df.reindex(index=['東京', '大阪', '愛知'])
df.reindex(columns=['ひよこまんじゅう', 'たこやき', 'ひつまぶし'])こんな感じで変更できます
Columns(カラム)名を変更したい
カラム名を変更したいときもあるかと思います。下記となります。
DataFrame.rename(columns={‘旧カラム名’: ‘新カラム名’})となり、コードは下記となります。
DataFrame.rename(columns={'A': 'a','B': 'b'})カラム名A→a、B→bとするコードです。カラム名が重複しているとエラーが発生してしまいますので、重複しないように心掛けないといけませんが、重複してしまった場合なこのコードを使用して重複を解消するようにしましょう。
特定の行(列)をカラム名に指定したい
Dataframeにした際にカラム名が勝手についてしまいますよね。
エクセルで読み込んだ際は、一番上の行にタイトルがついているとは限らず、
変なカラム名を修正したい場面は多くあるはず!。
そんな時は、下記サンプルコードを参考にしてみてください。
# ①まずはエクセルシートを読み込み(ここではファイル名はsample.xlsx)
df = pd.read_excel('sample.xlsx')
# ②Dataframeをリストに変更,to_list()メソッドを使用
list_title= df.iloc[7].to_list()
# ③Dataframeのコラムに先ほど作成したlistを代入
df.columns = list_title 列をカラム名に変更したい際は下記となりますが、あまりやらないかとは思います。
縦横数も異なりますし、行列が逆転しますので。。。
# ①まずはエクセルシートを読み込み(ここではファイル名はsample.xlsx)
df = pd.read_excel('sample.xlsx')
# ②Dataframeをリストに変更,to_list()メソッドを使用
list_title= df['従業員番号'].to_list()
# ③Dataframeのコラムに先ほど作成したlistを代入
df.columns = list_title Indexを削除したい
Pandasデータフレームをiloc等で切り出した際にindexが残ってて処理がうまくできないときありますよね。そういう時は1回リセットし、連番に振りなおすことができます。
df_reset=df.reset_index()ただ、このreset_index()ですが、使ってみるとわかりますが、もともとの連番がIndexとして挿入されてきたり、色々わからない動きをするので、引数を付ける必要があります。
df_reset=df.reset_index(level=None,drop=False,inplace=False,col_level=0)| level | MultiIndexのときに特定の階層のIndexオブジェクトだけ取り除きます (初期値 None) |
| drop | drop=Trueにすると、削除されたIndexオブジェクトの値を列データに挿入しない処理となります (初期値 False) 初期値がFalseのため、reset_indexの処理をした際にIndexの行が追加されてしまうので、この引数をTrueにする必要があります |
| inplace | 元のデータフレームに操作を反映するかどうかを指定します (初期値False) |
| col_level | カラムのレベルがMultiIndexのとき、どの回想に挿入するかを指定します (初期値 0) |
Indexを設定したい
削除したらIndexを設定したい場合もあるかと思います。
# columnsからIndexを設定するやり方です
df.set_index("選手",inplace =True)データ内の文字を抜き出す/削除等の加工をしたい
要素から文字を抜き出す
ExcelではMid,Left,Right関数を使って文字を抜き出しますが、Pythonではstr()メソッドです。
# 1~3番目を抜き出す
df.str[1:4]
# 2番目までを抜き出す
df.str[:2]抜き出した文字を使って新たなColumnを作りたい場合は下記となります。
df["特別客"] = df["客数"].str[2:3]不要な文字を抜き出す
いらない文字を削除はstrip()関数です。strip関数は前後から指定された文字を消去していきますが、消去対象以外の文字が現れればそこで処理がストップします。
特定の文字を指定して消去する場合は引数を指定するということをすればよいです。
df.str.strip("a")データ型を変更する
実際のデータはint,floatで出来ているわけではないので加工する技術が非常に重要になりますよね。データ分析の前にデータをきれいにする技術が必要なことを痛感されている方は多いはずです。ここではデータの書式が統一されているかどうかを事前に確認し、バラバラな場合は数値(int,float)に変換していきましょう。
| 関数 | |
| dtype | データ型の確認(指定の列) |
| dtypes | データ型の確認(全ての列) |
| astype(int) | 文字列から整数(int型)に変換 |
| astype(float) | 文字列から浮動小数点数(float型)に変換 |
まずは、1列だけfloatからintに変更するにはastype関数を使ってデータ型を変更します。
df["人口"].astype(int)ここでテクニックですが、数値にコロン(,)が入っている場合がありますよね。これはreplaceで取り除けばいいのですが、replace(‘,’,”, regex=True)のようにするのがポイントです。文字列の一部を置換したいのでregex=Trueが必要です。指定しないと,という値と完全一致するセル値しか置換されません。
データの結合をしたい(merge,concat)
データをつなげるにはさまざまな関数が用意されています。
下記データを使って説明していきます。
データを使いたい方は左記をダウンロードしてください。「data.csv」「data2.csv」
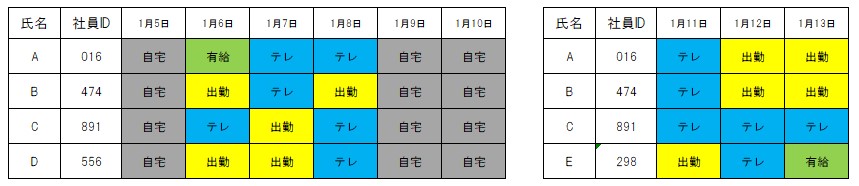
まずはコードを見てみましょう。
#まずはデータを読み込みます
import pandas as pd
df1 = pd.read_csv("data1.csv")
df2 = pd.read_csv("data2.csv")
#merge(結合)
pd.merge([df1,df2],how="inner") #内部結合
pd.merge([df1,df2],on="社員ID",how="left") #部分外部結合
pd.merge([df1,df2],on="社員ID",how="outer") #完全外部結合
#concat(連結)
pd.concat([df1,df2],axis=0)
pd.concat([df1,df2],axis=1) #axix=1は横方向に連結させますそれぞれの結果が下記になります。
pd.merge(df1,df2,how="inner")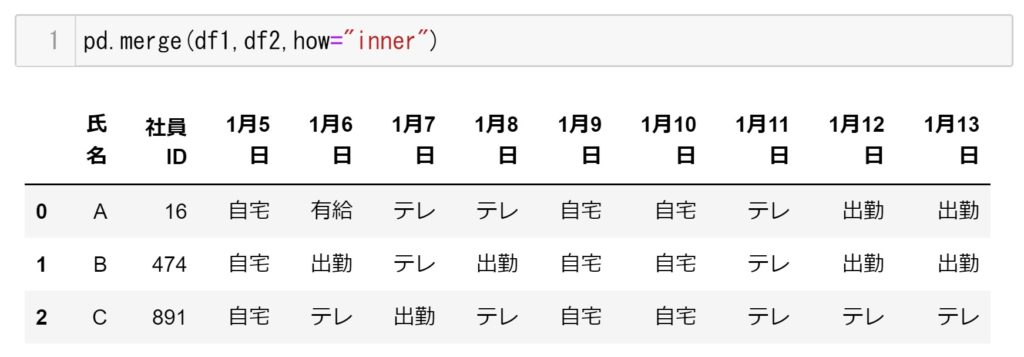
pd.merge(df1,df2,on="社員ID",how="left")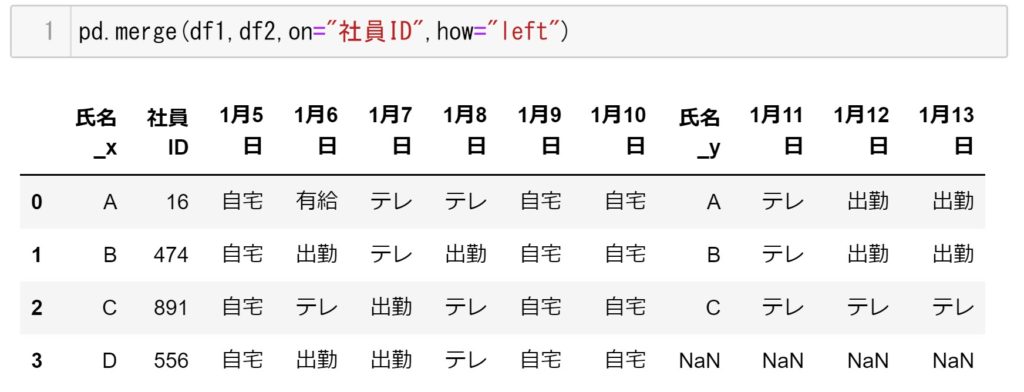
pd.merge(df1,df2,on="社員ID",how="outer")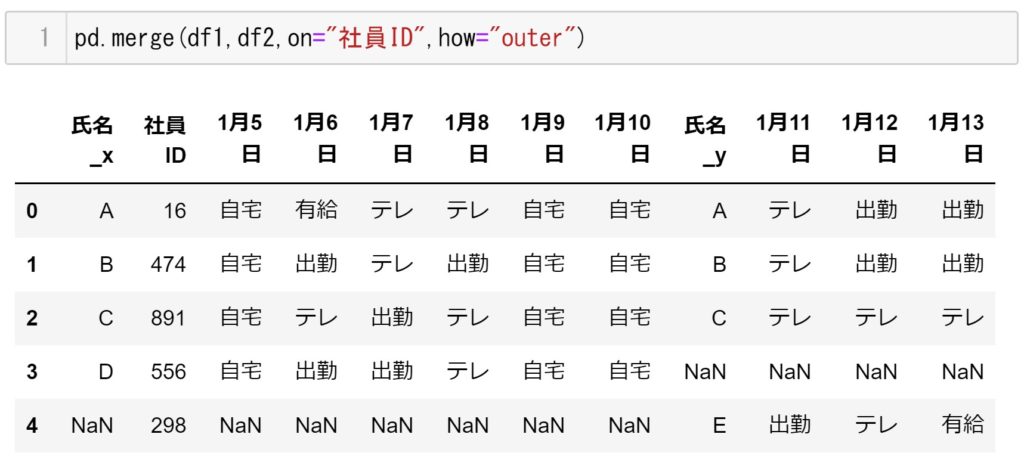
pd.concat([df1,df2],axis=0)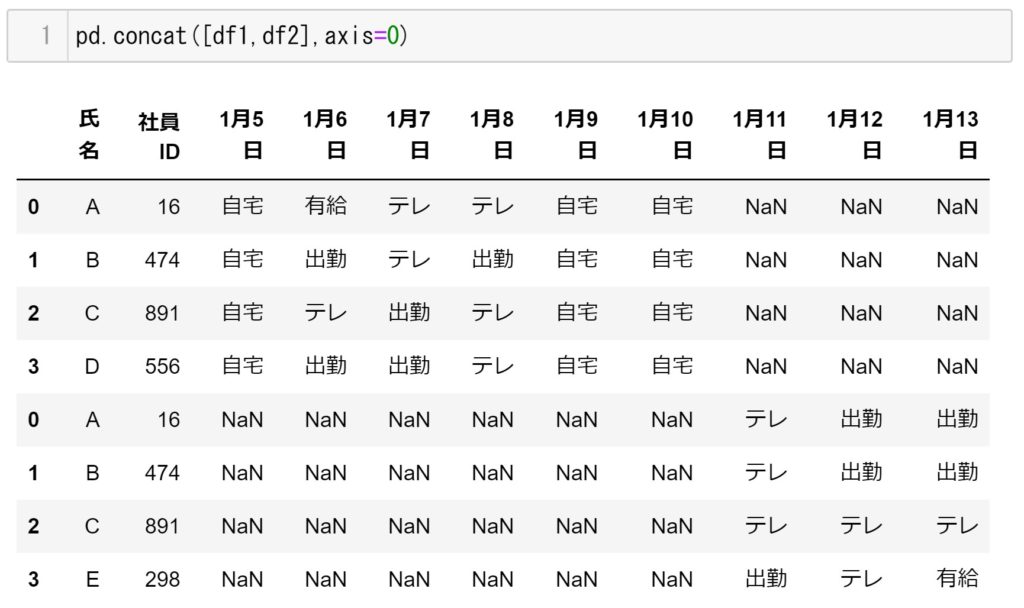
d.concat([df1,df2],axis=1)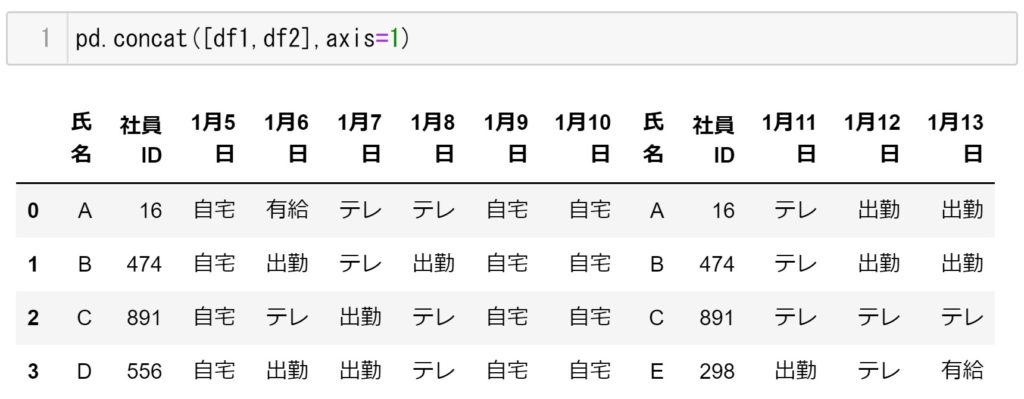
理解できましたでしょうか。
一度自分のデータでもしっかり理解するまで進めてくださいね。
欠損値の処理をしたい
ファイルを読み込んだとき、要素が空白だったりすると欠損値NaNだとみなされます。他人が作成したファイルだと欠損値が多かったりしますよね。こんなときは、除外するか穴埋め(置き換え)するようにしましょう。除外するにはdropna()メソッド、穴埋めするにはfillna()メソッドを使います。
欠損値を把握したい
欠損値を処理するのにまず、どの程度の欠損が含まれているかを把握しないといけません。これにはisnull()メソッドをしようするのですが、コード事例としては下記になります。
# 学習データの欠損状況
df.isnull().sum()[df.isnull().sum()>0].sort_values(ascending=False)これを実行すると各カラムの欠損値の数がわかります。
また、下記コードで欠損値のデータ型がわかります。
# 欠損を含むカラムのデータ型を確認
na_list = df.isnull().sum()[df.isnull().sum()>0].index.tolist() # 欠損を含むカラムをリスト化
df[na_list].dtypes.sort_values() #データ型これを活用して前処理に役立てましょう!
欠損値を削除したい dropna()
dropna()関数ですが欠損値を削除する関数です。
重要ポイントですがinplace=Trueにしないと元のデータに変更は反映されないので注意しましょう。
上記で作成した、pd.concat([df1,df2])は欠損値が全行に含まれていますが、これを使って勉強してみましょう。
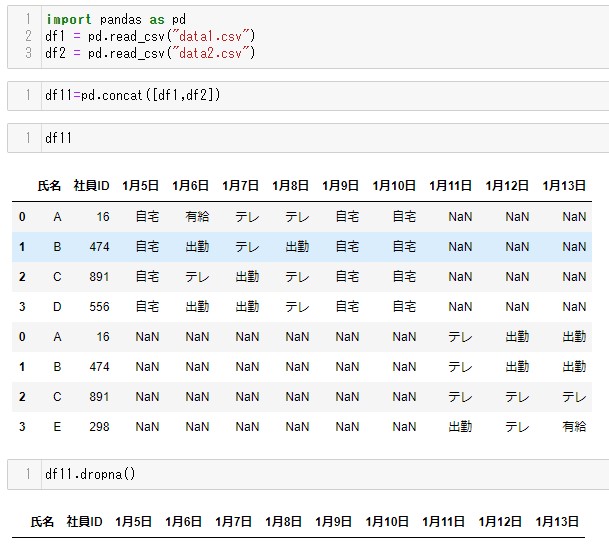
全行に欠損値が入っているのですべて消えてしまいました(笑)。
もちろんこれでは使い勝手が悪いので下記紹介しますね。
# すべてが欠損値となっている行のみを削除
df11.dropna(how='all')
# 1月5日に欠損値が含まれる行だけを削除する
df11.dropna(subset=['1月5日'])
# 欠損値でないところが3つ以上残っていれば削除しない
df11.dropna(thresh=3)
# axisで欠損値を含む行を削除するか、列を削除するかを指定できます。(axis = 1)で列を削除できます)
df11.dropna(axis=1)特定の条件を満たした行を削除したい
これはdropna()を使わない方法がいいかと思います。
df = df[df['1月5日'] != "自宅"]となります。
初歩的な手法ですがこれがよいかと思いますのでご紹介しておきます。
欠損値に数値を入れたい fillna()
最初の引数で穴埋めする値を指定して使います。0で埋めたかったらfillna(0)と指定します。
また特定のカラムのみ欠損値に数値を入れる場合は以下のコードとなります
df['LotFrontage'] = df['LotFrontage'].fillna(method='ffill')fillna()は、引数をmethod = ‘ffill’, method = ‘bfill’と指定すると、欠損した要素に同じ列内の別の値に置き換えます。method = ‘ffill’とした場合は、ひとつ前の数字をいれて、method = ‘bfill’とした場合は、ひとつ前の数値をいれて欠損値の穴埋めを行います。
2つの文字列を結合したい
複数行の文字列を結合したい際に、Nanが含まれているとうまくいきません。
Pandasでは2つの文字列を結合すると、nan値は無視されます。
そこで、fillnaを活用して空のstrを渡す必要があります。
df_Sample = df.iloc[7].fillna(method='ffill').fillna('') + df.iloc[8].fillna('')Dataframeの7行目と8行目の文字列を結合したいのですが、
それぞれにNan値が含まれているため、それを除去するためfillna()関数を使って空strを代入しています。
また、7行目の処理に.fillna(method=’ffill)を使っているのは、Nan値を埋める必要があるためでした。
重複確認と重複の削除をしたい
Pandasでの重複判定したい(重複データを取り除きたい)
DataFrameやSeriesにはduplicated()という重複を判定するメソッドがあるので、これを利用してみましょう。下記のDataFrameで試してみます。
import pandas as pd
df1 = pd.DataFrame([[200,100,200],[3000,4,500],[200,300,200],[200,100,200]], /
index =['愛知','大阪','福岡','奈良'], columns=['売上','仕入れ個数','客数'])このDataFrameに対しduplicated()メソッドを適用してみると、重複されるところはTrueで返されるのがお分かりいただけるかと思います。またduplicated(keep=”first”)とすると重複要素の先頭のみがFalseと判定される。他のkeepオプションは下表を参照にしてください。
| “first”(デフォルト) | 重複要素の先頭のみFalseと判定する |
| “last” | 重複要素の末尾のみFalseと判定する |
| False | 重複要素はすべてTrueと判定する |
この時下記コードで重複を削除することができます。
df[~df.duplicated()]Qiitaさんの説明が非常にわかりやすく参考にさせていただきました。
重複確認をしたい
主なduplicatedメソッド
①duplicated
すべての列で完全に重複する行を判定
②duplicated(keep=’last’)
最初の行を重複判定(これより後ろを残したい場合に使う)
逆に最初を残したい場合は’first’とする
③duplicated(keep=False)
④duplicated([‘aaa’])
指定した列で重複した行を判定
⑤duplicated([‘aaa’,’bbb’])
指定した列で重複した行を判定
いずれも重複判定(True)の場合に重複判定
重複の削除をしたい
主なdrop_duplicatesメソッド
①drop_duplicates
②drop_duplicates(keep=’last’)
③drop_duplicates(keep=False)
④drop_duplicates([‘aaa’])
⑤drop_duplicates([‘aaa’,’bbb’])
ピボットテーブルの作成(Pandas活用)をしたい
ピボットテーブルの作成方法です。
# DataFrame.pivot_table(values = ["集計値1","集計値2"], index = ["行1","行2"], columns = "列")
# 上記がピボットテーブルの基本の文法となります。
# aggfunc="sum"とすれば合計が加算されます
df_pivot = pd.pivot_table(df, index='メーカー名', aggfunc="sum")これで”メーカ名”を縦軸としたピボットテーブルが完成します。
aggfuncにはsum以外にmax、min、count、mean(平均)などが指定できます