
業務でOfficeを活用されていることは多いのではないでしょうか? PythonでExcel,Outlookを操作したいと思うのは至極当然のことかと思います(笑)。ここではPythonでどのように操作していくかを勉強していければと思います。
ただ筆者の思いですが、
Excelを操作するには、Pandasを使ったほうが
Excelを長年使ってきた方には操作性がいいかと思いますよ。
目次
「Python」で「Excel」を操作しよう!
Pythonでエクセル(Excel)と連携させるためのライブラリを読み込もう
Pythonは様々なライブラリ群がありますが、エクセルを使うためにはライブラリを読み込まないといけません。インストール方法は他の人に任せるとして(笑)、使用するライブラリとimportのコードを紹介しておきます。
import openpyxlこれだけです。。
ほかに「pywin32」もありますが、ここでは「openpyxl」を使う方法を中心に紹介していきます。
PythonでExcel(エクセル)データの抽出をしよう
エクセル「ブック,シート」の読み込みをしよう(基本)
下記コードを参考にしてください。
①ブックの読み込み
②シートの読み込み
③セルの読み込み
このあとprintするという単純なコードになっていますが、これを応用すればエクセルを読み込むことができると思います。
# ライブラリの読み込み
import openpyxl
# ブックの読み込み(名称は”test.xlsx”)
wb = openpyxl.load_workbook("test.xlsx")
# シートの読み込み([0]は1番最初のシートを意味します)
ws1 = wb.worksheets[0]
# セルを番号で指定し、セルの値を読み込み ※(1,1)は「A1セル」
ws1a1 = ws1.cell(1,1).value
# シートの読み込み(シートの名称で指定、シート名は["A2"])
ws1a2 = ws1["A2"]
# ワークシート名を取得
ws1n = ws1.title
print("sheet1は" + ws1n)
print(ws1)
print(ws1a1)
print(ws1a2)
# 下コードは復習がてら確認してみてください
ws2 = wb["Sheet2"]
ws2n = ws2.title
print("Sheet2は" + ws2n)
ws2b2 = ws2.cell(2,2).value
print("ws2.cell(2,2).valueは→" + ws2b2)
上記は読み込みの基本となりますが、1つ1つ読み込んでいくわけにもいきませんよね。下記がまとめて読み込むコードとなりますが、値を読み込むというよりセルオブジェクトを読み込むことになります。
# セルオブジェクトを取得
rng1 = ws2["A1:C3"]
print(rng1)実行すると下記となると思います。これはセルA1~C3までの範囲のセルオブジェクトを読み込んだ結果が表現されています。rng1にこのオブジェクト群を格納したことになります。
((<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.B1>, <Cell 'Sheet2'.C1>), (<Cell 'Sheet2'.A2>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.C2>), (<Cell 'Sheet2'.A3>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.C3>))Cellオブジェクトのプロパティは以下のようなものがあります。これらを取り出すコードが表の下に記載してありますので、参考にして下さい。
| Cell.column | セルの横軸の座標 |
| Cell.row | セルの縦軸の座標 |
| Cell.coordinate | セルのエクセル座標 |
| Cell.value | セルの値 |
import openpyxl
wb = openpyxl.load_workbook("test.xlsx")
ws1 = wb["Sheet1"]
cell_c5 = sheet['c5']
print('Cell.column 横軸の座標:', cell_c5.column)
print('Cell.row 縦軸の座標:', cell_c5.row)
print('Cell.coordinate Excel座標:', cell_c5.coordinate)
print('Cell.value セルの値:', cell_c5.value)for文を使ったエクセルデータの読み込みをしよう(リストに読み込み①)
またfor文を使ってもう少し効率的に読み込むこともできます。
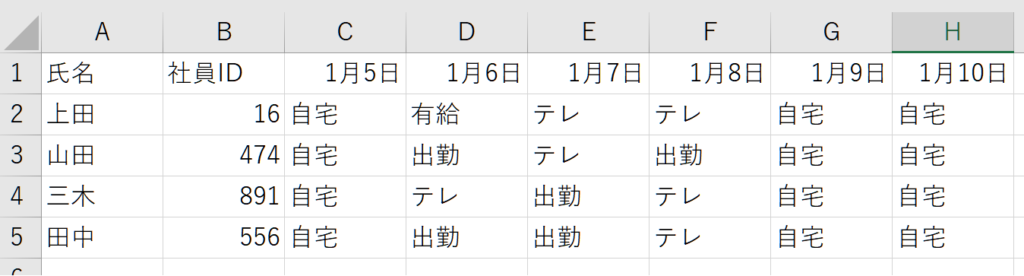
エクセルに下記の行動予定表があるとしましょう。これをfor文を使って読み込みます。
「data1.xlsx」を下記と設定して説明しますね。
import openpyxl
# 社員リストの設定
member_koudou = []
# エクセルファイルの取り込み
wb = openpyxl.load_workbook("data1.xlsx")
ws = wb["sheet1"]
# iter_rows()メソッドで2行目から開始する
for row in ws.iter_rows(min_row=2) :
values = []
for c in row : # cはセルを意味して設定した変数(ここはなんでもよい)
values.append(c.value)
member_koudou.append(values)
print(member_koudou)[[‘上田’, 16, ‘自宅’, ‘有給’, ‘テレ’, ‘テレ’, ‘自宅’, ‘自宅’],
[‘山田’, 474, ‘自宅’, ‘出勤’, ‘テレ’, ‘出勤’, ‘自宅’, ‘自宅’],
[‘三木’, 891, ‘自宅’, ‘テレ’, ‘出勤’, ‘テレ’, ‘自宅’, ‘自宅’],
[‘田中’, 556, ‘自宅’, ‘出勤’, ‘出勤’, ‘テレ’, ‘自宅’, ‘自宅’]]
このように読み取ることができると思います。
このコードのポイントはiter_rows()メソッドかと思います。
ここでは、「min_row=2」を指定して2行目から読み込むことにしていますが、これも含めて下記のメソッドがあります。これらを 「,(コロン)」で区切ることによって指定することができます。
| min_row | 開始行 |
| max_row | 終了行 |
| min_col | 開始列 |
| max_col | 終了列 |
このほかにコード内に説明文は記載してあるので参考にしてもらえればと思います。このメソッドを利用してエクセルの最大行列数を取得することができます。コードは下記になりますよ。
# 最大行を取得
ブック変数[シート名].max_row
book['Sheet1'].max_row
# 最大列を取得
ブック変数[シート名].max_column
book['Sheet1'].max_columnfor文を使ったエクセルデータの読み込みをしよう(リストに読み込み②)
下記のコードは一度読み込んだデータを使って値を出し、新たに書き込むというコートです。
import openpyxl
#ファイルdata1.xlsxを開く
wb = openpyxl.load_workbook('data1.xlsx')
ws = wb["sheet1"]
#セルの値を読み込んで加工し書き込む
for i in range(2,ws.max_row+1):
name = ws.cell(row=i, column=1).value
id = ws.cell(row=i, column=2).value
comment = str(name)+"の社員IDは"+str(id)+"です"
print (comment)
ws.cell(row=i, column=9).value = comment
#ファイルを保存
wb.save('data2.xlsx')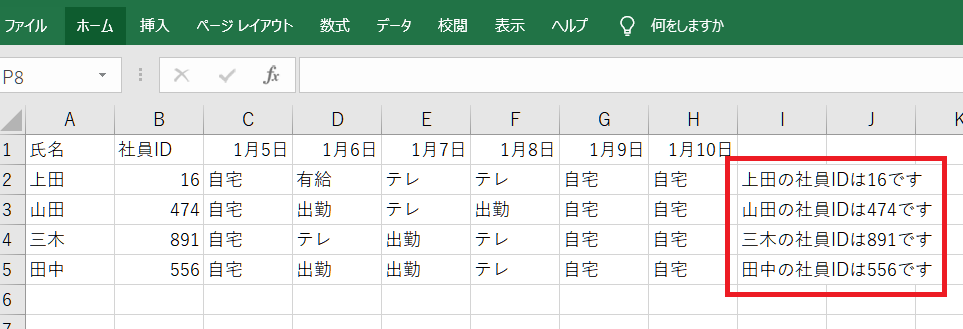
このように氏名と社員IDから新たなブックを作って保存しています。
for~Range()で読み込んでいるのですが、ポイントとなっているのは
range(2,ws.max_row+1)かと思います。Pythonにおけるエクセルの行数は1からはじまるので、2行目から読み込みたい場合は2からにする必要があるのと、「ws.max_row」に1を足さないと最終行まで読み込みません。Pythonの仕様なのでしかたないですが、少々わかりにくいですよね。ここは初心者にとって間違えやすいポイントとなるので気を付けましょう。
for文を使ったエクセルデータの読み込みをしよう(辞書に読み込み)
次はfor文を使って辞書に読み込んでみましょう。
import openpyxl
# エクセルファイルの取り込み
wb = openpyxl.load_workbook('data1.xlsx')
ws = wb["sheet1"]
# 1行目(列名のセル)
header_cells = ws[1]
# 2行目以降(データ)
syain_list = []
for row in ws.iter_rows(min_row=2):
row_dic = {}
# zip関数を用いてヘッダーと各値をリンクさせ辞書に格納
for head, r in zip(header_cells, row):
row_dic[head.value] = r.value
syain_list.append(row_dic)
print(syain_list)[{‘氏名’: ‘上田’, ‘社員ID’: 16, ‘1月5日’: ‘自宅’, ‘1月6日’: ‘有給’, ‘1月7日’: ‘テレ’, ‘1月8日’: ‘テレ’, ‘1月9日’: ‘自宅’, ‘1月10日’: ‘自宅’},
{‘氏名’: ‘山田’, ‘社員ID’: 474, ‘1月5日’: ‘自宅’, ‘1月6日’: ‘出勤’, ‘1月7日’: ‘テレ’, ‘1月8日’: ‘出勤’, ‘1月9日’: ‘自宅’, ‘1月10日’: ‘自宅’},
{‘氏名’: ‘三木’, ‘社員ID’: 891, ‘1月5日’: ‘自宅’, ‘1月6日’: ‘テレ’, ‘1月7日’: ‘出勤’, ‘1月8日’: ‘テレ’, ‘1月9日’: ‘自宅’, ‘1月10日’: ‘自宅’},
{‘氏名’: ‘田中’, ‘社員ID’: 556, ‘1月5日’: ‘自宅’, ‘1月6日’: ‘出勤’, ‘1月7日’: ‘出勤’, ‘1月8日’: ‘テレ’, ‘1月9日’: ‘自宅’, ‘1月10日’: ‘自宅’}]
これで辞書に読み込めました。
PythonでExcel(エクセル)データを並べ替えてみよう
上記で作成した辞書をソートしてみましょう。
import openpyxl
# エクセルファイルの取り込み
wb = openpyxl.load_workbook('data1.xlsx')
ws = wb["sheet1"]
# 1行目(列名のセル)
header_cells = ws[1]
# 2行目以降(データ)
syain_list = []
for row in ws.iter_rows(min_row=2):
row_dic = {}
# zip関数を用いてヘッダーと各値をリンクさせ辞書に格納
for head, r in zip(header_cells, row):
row_dic[head.value] = r.value
syain_list.append(row_dic)
# sortedメソッドで社員IDをキーにしてソート
sorted_syain_list = sorted(syain_list, key=itemgetter("社員ID"))
# pprintで見やすく表示
pprint(sorted_syain_list, sort_dicts=False)ここではsortedメソッドを使用して”社員ID”をキーにしてソートしています。
またpprintは「データ出力の整然化」と公式HPに記載されているように表示がとてもみやすくなります。このエクセルを使うときはこれをぜひ活用しましょう!
「Python」で「Outlook」を操作しよう!
Outlookのフォルダにあるメールを読み込んでDataFrameにしてみよう
フォルダ内にあるメールを整理するのにOutlookを使っているかと思いますが、Excel化するともうすこし便利なのに……と思うときがあるかと思います。ここではサンプルコードを解説していきますので活用してもらえればと思います。
import win32com.client
import pandas as pd
outlook = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI")
inbox = outlook.GetDefaultFolder(6)
folders = inbox.Folders
devopsFolder = folders('データ読み込みフォルダ')
messages = devopsFolder.Items
df_mail = pd.DataFrame()
i = 0
for message in messages:
df_mail.loc[i,"subject"] = str(message.Subject)
df_mail.loc[i,"sender"] = str(message.Sender)
df_mail.loc[i,"body"] = str(message.body)
i = i+1
df_mail.to_csv("mail.csv",encoding='utf_8_sig')それでは下記で順番に解説していきますね~。
Pythonでアウトルック(Outlook)と連携させるためのライブラリを読み込もう
# ライブラリ読み込み
import win32com.client
# outlookの定義(読み込みたいフォルダの定義)
outlook = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI")
inbox = outlook.GetDefaultFolder(6)
folders = inbox.Folders
devopsFolder = folders('データ読み込みフォルダ')
messages = devopsFolder.Itemsライブラリの読み込みとoutlookの定義をします。
また、outlookの定義と記載していますが、まずはこれをコピペして持ってきてください。
コード内の ‘データ読み込みフォルダ’ は読み込みたい名称にしてくださいね。
読み込んだメッセージを(題名、送信者、本文)切り分けよう
# Pandasライブラリ読み込み
import pandas as pd
# データフレームの定義
df_mail = pd.DataFrame()
#データフレームにそれぞれを格納
i = 0
for message in messages:
df_mail.loc[i,"subject"] = str(message.Subject) # 題名を格納
df_mail.loc[i,"sender"] = str(message.Sender) # 送信者を格納
df_mail.loc[i,"body"] = str(message.body) # 本文を格納
i = i+1Pandasで処理しているので少しややこしくなっていますが、Outlookから読み込んだメールはmessageオブジェクトに格納されています。下表のようにmessageからは情報を取得できるので参考にしてください。様々な属性を持っていますよ。
| subject | 題名 |
| sender | 送信者 |
| body | 本文 |
| to | 宛先 |
| cc | Cc |
Outlookで読み込んだデータをCSVファイルに書き出そう
# CSVファイルに書き出し
df_mail.to_csv("mail.csv",encoding='utf_8_sig')最後にCSVファイルに書き出しましょう。